This invention presents a new design for domain-specific question-answering systems called QuIM-RAG. It improves Retrieval-Augmented Generation (RAG) pipelines by using inverted question matching. Instead of embedding document parts directly, the system uses a language model to create simple questions for each chunk, reflecting its main idea. These questions are then embedded, quantized, and stored in an organized index. During query time, a user's natural language question is also embedded and quantized to match the closest prototype, enabling efficient and meaningful retrieval based on semantic intent. For complex queries, the system incorporates a divide-and-conquer mechanism that decomposes the query into sub-questions, applies multiple sanity checks for consistency and logic, and aggregates the results only if confidence thresholds are met. Otherwise, it invokes a fallback mechanism for clarification or human interaction. This innovation significantly improves retrieval accuracy, efficiency, and user trust by ensuring responses are relevant, context-aware, and of high confidence.
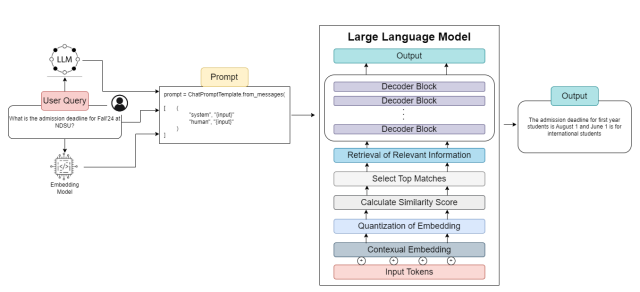
Overall Retrieval and Generation Architecture for RAG
Benefits
-
Inverted question-based retrieval instead of chunk-based
-
Embedding and quantization of representative questions for efficient prototype matching
-
Semantic alignment via question intent rather than lexical similarity
-
Divide-and-conquer mechanism for complex queries with multi-step sanity checks
-
Confidence-calibrated fallback handling to avoid hallucinations
Applications
-
Conversational AI assistants for universities and educational portals
-
Customer service automation in regulated industries (banking, insurance)
-
Clinical decision support or patient-facing chatbots
-
Internal knowledge retrieval systems for corporations
-
AI-based legal case summarizers and compliance tools
Patents
This technology has a Patent pending and is available for licensing/partnering opportunities.